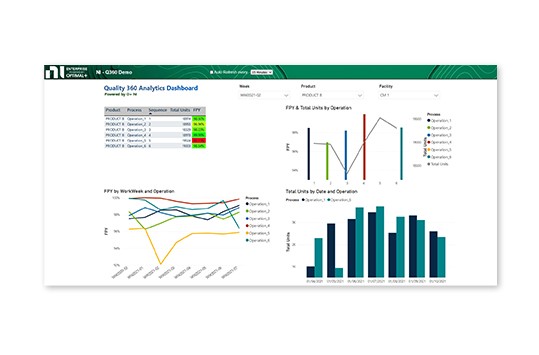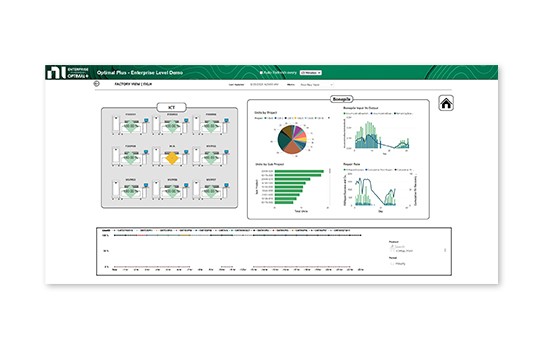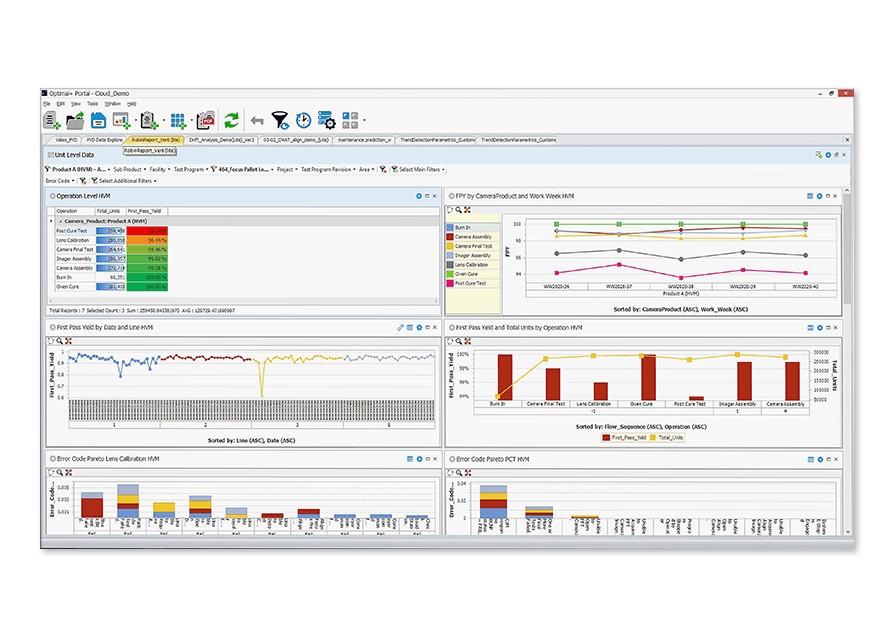
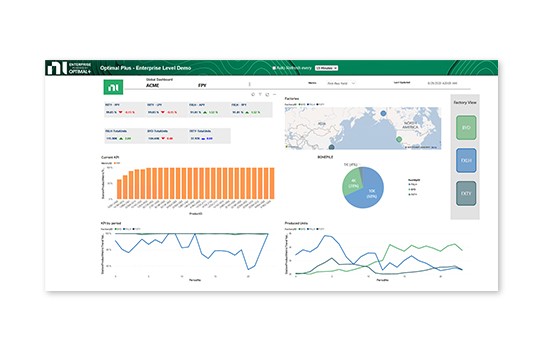
Using OptimalPlus GO software, you can connect and correlate product data from multiple systems.
- Create a consistent data model accessible to everyone
- Build dashboards and monitor data across all product stages
- Connect with thousands of data sources from testers to enterprise resource planning (ERP)
- Support for 90% of semiconductor outsourced semiconductor assembly and test (OSAT)